원시 데이터를
가치 있는 정보로
변환합니다
드래그 앤 드롭으로 설계하는
데이터 가공 파이프라인
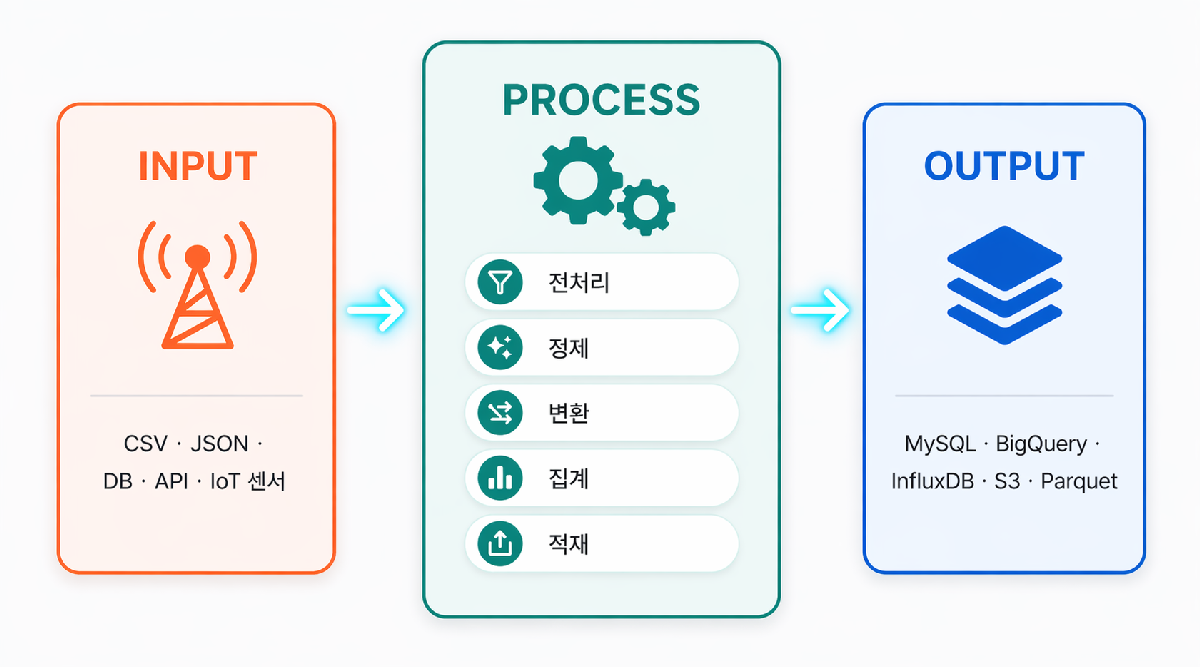
테크블루의 데이터 가공 솔루션은 코딩 없이 직관적인 드래그 앤 드롭 방식으로 복잡한 데이터 가공 프로세스를 설계할 수 있습니다. 다양한 소스의 데이터를 통합·융합하고, 목적에 맞게 변환한 후 Data Warehouse에 체계적으로 적재합니다.
- 코딩 없이 드래그&드롭으로 파이프라인 설계
- 50+ 가공 블록 라이브러리 (필터·정렬·집계·변환 등)
- 배치 + 실시간 스트리밍 가공 동시 지원
- 가공 전/후 실시간 미리보기 (Data Preview)
- 스케줄러 기반 완전 자동화 (이벤트 트리거 포함)
- 이기종 DW/DB 자동 적재 (MySQL·PostgreSQL·BigQuery 등)
- 전체 가공 이력 로깅 및 감사 추적
핵심 기능
데이터 수집부터 활용까지, 가공의 모든 과정을 지원합니다
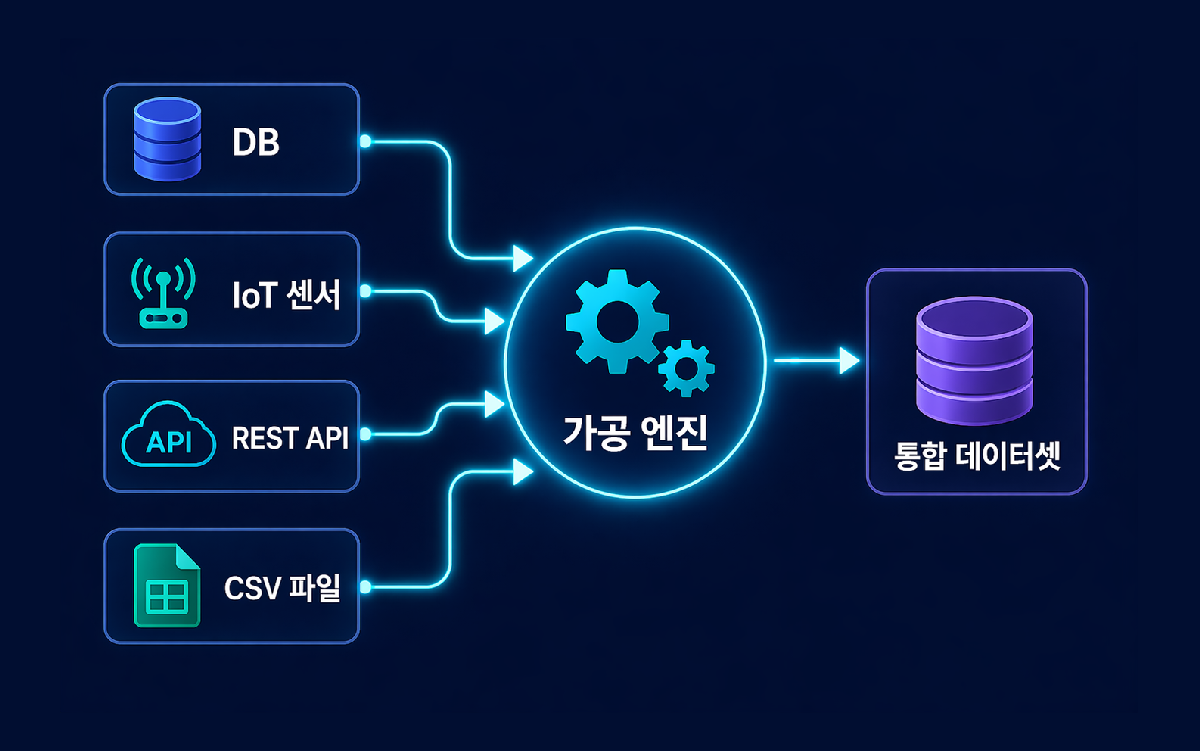
다양한 소스의 데이터를 하나로
서로 다른 형식, 주기, 위치에서 수집된 데이터를 하나의 통합 데이터셋으로 융합합니다. 스키마 매핑, 데이터 타입 변환, 키 매칭을 자동 처리합니다.
- 이기종 데이터 스키마 자동 매핑
- 시계열 데이터 시간축 정렬 (Time Alignment)
- 다중 소스 Join / Union 처리
- 메타데이터 자동 태깅 및 분류
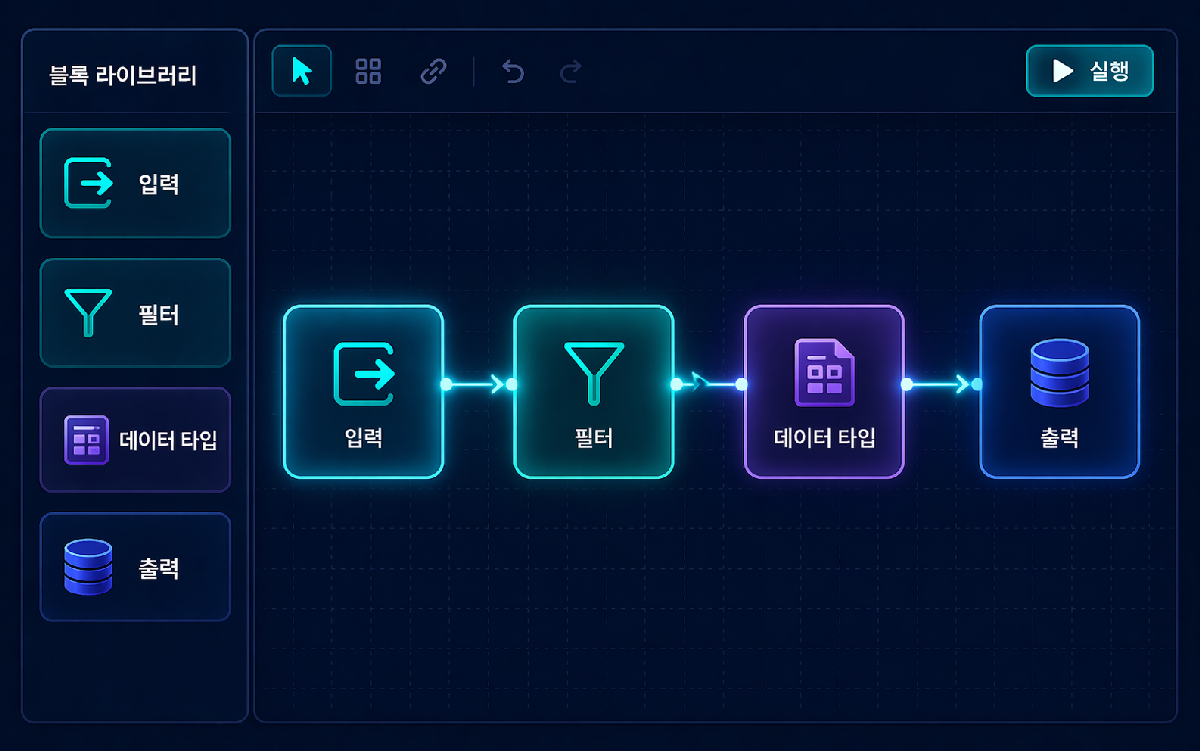
코딩 없이 가공 프로세스를 설계
드래그 앤 드롭으로 가공 워크플로우를 설계할 수 있습니다. 자주 사용하는 가공 블록을 조합하여 복잡한 파이프라인도 시각적으로 구성합니다.
- 가공 블록 라이브러리 (50+ 종류)
- 워크플로우 시각적 편집기
- 실시간 미리보기 (가공 전/후 데이터 비교)
- 워크플로우 템플릿 저장 및 재사용
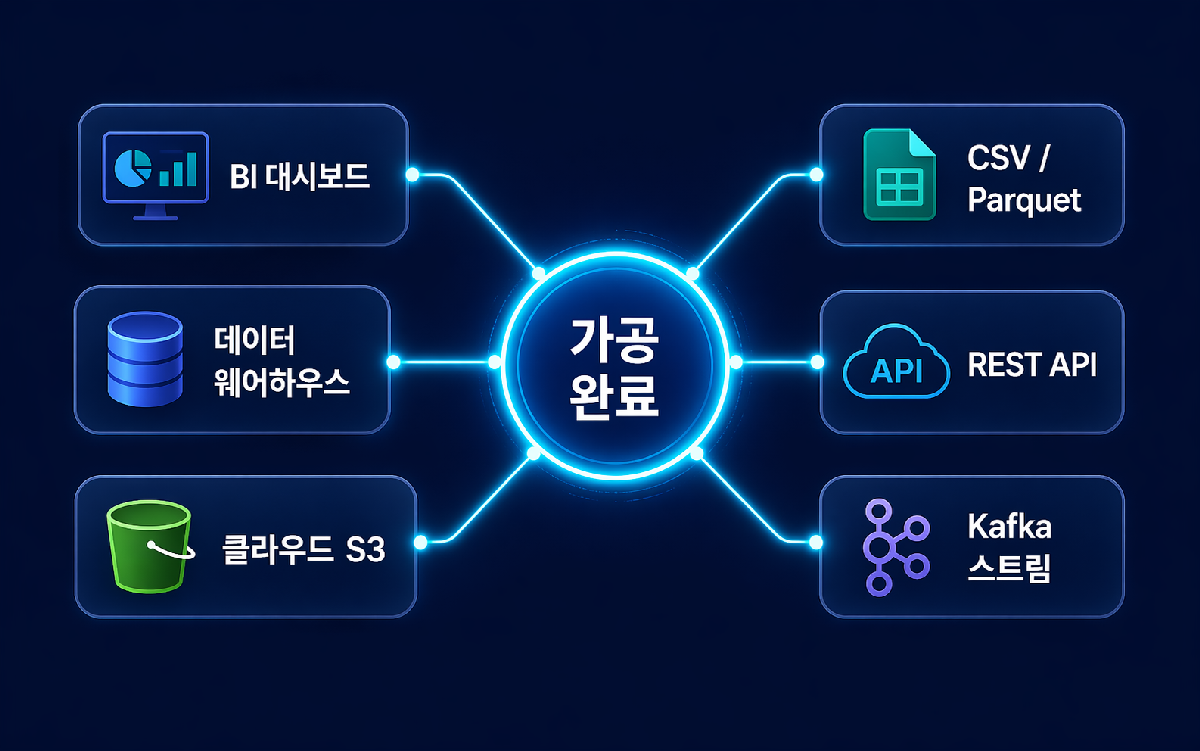
원하는 형태로, 원하는 곳에
가공 완료된 데이터를 다양한 형식으로 출력하고 다양한 목적지로 전달합니다.
- 출력 형식: REST API · CSV · Excel · JSON · Parquet
- 목적지: Database · Data Warehouse · 클라우드 스토리지
- 스트리밍 출력: Kafka · WebSocket 실시간 전달
- 외부 시스템 연동: ERP · MES · BI 도구
한 번 설계하면, 자동으로 실행
스케줄러 기반 자동 가공 파이프라인으로 반복 작업을 완전 자동화합니다. 이벤트 트리거 방식으로 데이터 도착 시 즉시 자동 실행합니다.
- Cron 기반 스케줄링 (분/시/일/주/월)
- 이벤트 트리거 (데이터 도착 시 자동 실행)
- 처리 현황 모니터링 대시보드
- 실패 시 자동 재시도 및 알림
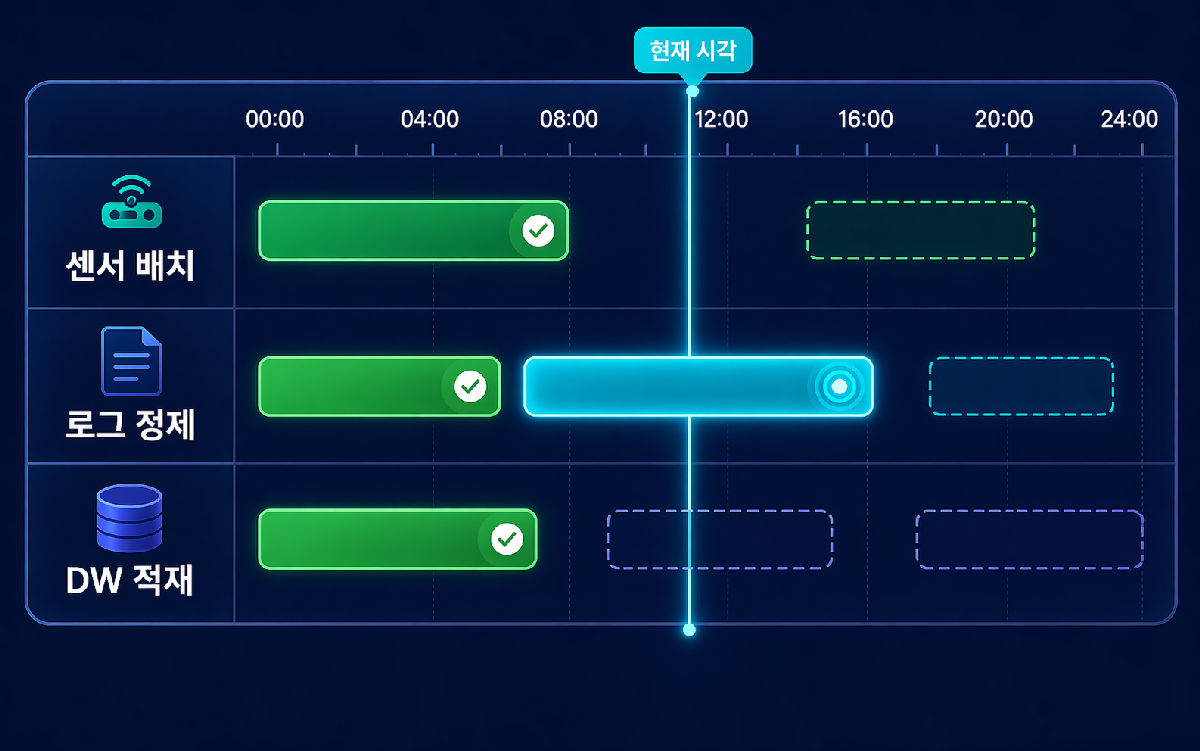
데이터 팩토리 아키텍처
수집부터 활용까지, End-to-End 데이터 가공 파이프라인
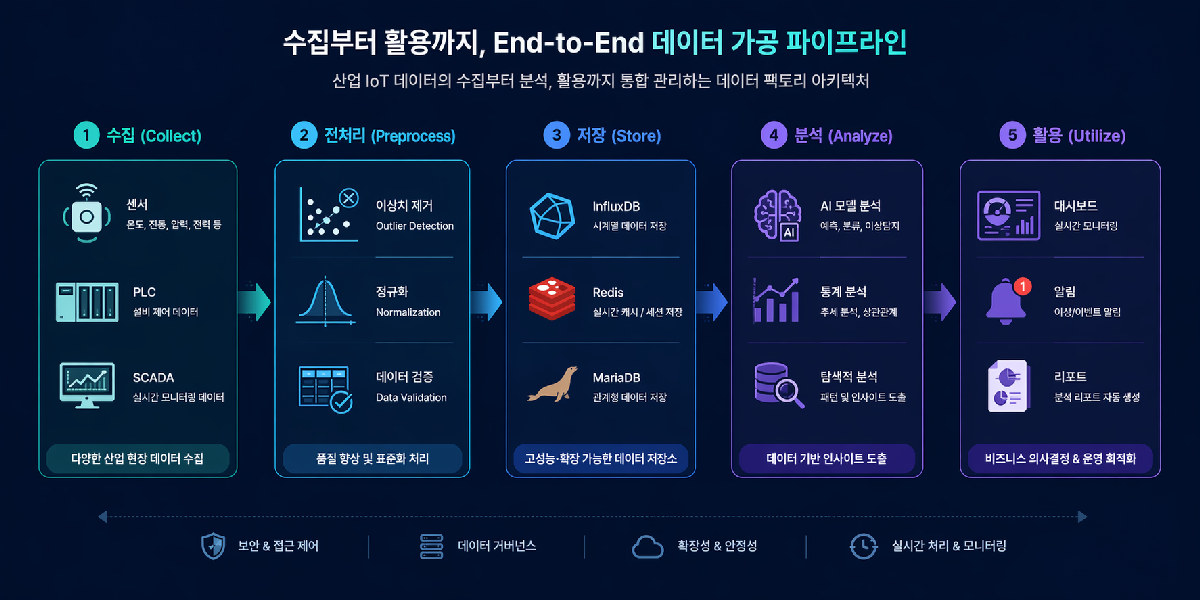
IoT·로그·API·DB 등 다양한 소스에서 원시 데이터를 수집합니다.
실시간 스트리밍 또는 배치 방식으로 가공 엔진에 데이터를 인입합니다.
정제·변환·필터링·집계 등 드래그&드롭으로 설계된 가공 로직을 자동 실행합니다.
구조화된 데이터를 DW에 체계적으로 적재합니다. 스키마 버전 관리 포함.
시각화·리포트·AI 학습·파생 데이터 등 다양한 방식으로 활용합니다.
데이터 가공 솔루션 도입 효과
수작업과 자동화 파이프라인의 명확한 차이를 확인하세요
어떤 가공이든 가능합니다
50개 이상의 가공 블록으로 어떤 데이터 처리 요구도 해결합니다
- NULL 값 → 평균/중앙값/전후값 대체
- 이상치(Outlier) 자동 제거 또는 보정
- 중복 레코드 감지 및 제거
- 인코딩 오류 자동 수정
- String → Integer / Float 변환
- 날짜 형식 통일 (YYYY-MM-DD)
- 단위 변환 (°F→°C, inch→mm)
- 불리언 변환 (Yes/No → 1/0)
- 시간 윈도우 집계 (분·시·일·월)
- 그룹별 집계 (부서·장비·센서)
- 롤링 집계 (이동 평균, 누적 합계)
- 피벗 테이블 자동 생성
- 다중 조건 필터 (AND / OR / NOT)
- 정규식(RegEx) 기반 문자열 필터
- 조건별 파이프라인 분기 처리
- 날짜 범위 필터
- Inner / Left / Right / Full Outer Join
- 시계열 기반 Time-Join
- 퍼지 매칭 (유사 키 자동 매핑)
- Union (스키마 다른 테이블 통합)
- 수식 기반 파생 컬럼 (A*B, A-B)
- 조건부 파생 (IF/CASE WHEN)
- 시간 파생 (경과 시간, 요일, 시간대)
- 텍스트 파생 (부분 추출, 패턴 변환)
- Min-Max 정규화 (0~1 범위)
- Z-Score 표준화
- Log 변환 (왜도 보정)
- 원-핫 인코딩 (범주형→수치형)
- CSV / JSON / Parquet / Excel 변환
- 문자 인코딩 변환 (UTF-8 표준화)
- XML / EDI 포맷 생성
- API / DB / 클라우드 자동 전송
카드에 마우스를 올리거나 터치하면 상세 정보를 확인할 수 있습니다
가공 플랫폼의 처리 역량
실제 운영 환경에서 검증된 성능 지표
수작업 대비 90% 이상 가공 시간 단축
자동 전처리·정제로 확보되는 데이터 품질
전처리·변환·집계·출력 등 50가지 이상
설계 후 무인 자동 실행 (스케줄러 + 이벤트 트리거)
24/7 무중단 가공 파이프라인
MySQL · PostgreSQL · InfluxDB 등
도입 프로세스
요건 분석부터 운영 이관까지 평균 8~10주 소요
현재 데이터 환경과 가공 요구사항을 분석합니다. 데이터 소스, 가공 로직, 출력 형식, 자동화 범위를 정의합니다.
- 현재 데이터 파이프라인 현황 파악
- 가공 병목·오류 구간 식별
- 목표 데이터 품질 및 처리 속도 정의
분석 결과에 기반하여 가공 파이프라인 아키텍처를 설계합니다. 데이터 흐름도, 가공 규칙, 스케줄링 정책을 수립합니다.
- 데이터 흐름 다이어그램(DFD) 작성
- 가공 블록 선정 및 파이프라인 설계
- DW 스키마 설계
가공 워크플로우를 구축하고, 커스텀 가공 로직을 개발합니다. DW 스키마를 구현하고 데이터 적재 파이프라인을 구성합니다.
- 드래그&드롭 파이프라인 구성
- 커스텀 가공 블록 개발
- DW 구축 및 적재 파이프라인 설정
실제 데이터로 가공 파이프라인을 시운전합니다. 가공 결과의 정확성, 성능, 안정성을 검증합니다.
- 실제 데이터 기반 시운전
- 데이터 품질 지표 측정 (정확도·완결성)
- 처리 성능 부하 테스트
운영 환경에 배포하고 운영 교육을 실시합니다. 모니터링 체계를 구축하고 운영 매뉴얼을 제공합니다.
- 운영 서버 배포 및 스케줄러 활성화
- 사용자 교육 (파이프라인 관리)
- 모니터링 대시보드 설정
데이터 가공 파이프라인 구축이
필요하신가요?
원시 데이터를 가치 있는 정보로 변환하는 자동화 파이프라인을 구축해 드립니다.
드래그 앤 드롭으로 누구나 쉽게 설계하고, 자동으로 실행되는 파이프라인을 경험하세요.